AI Engineering, Decoded.
Fifteen frames that separate people building real AI products from people still tweaking prompts in a chat window.
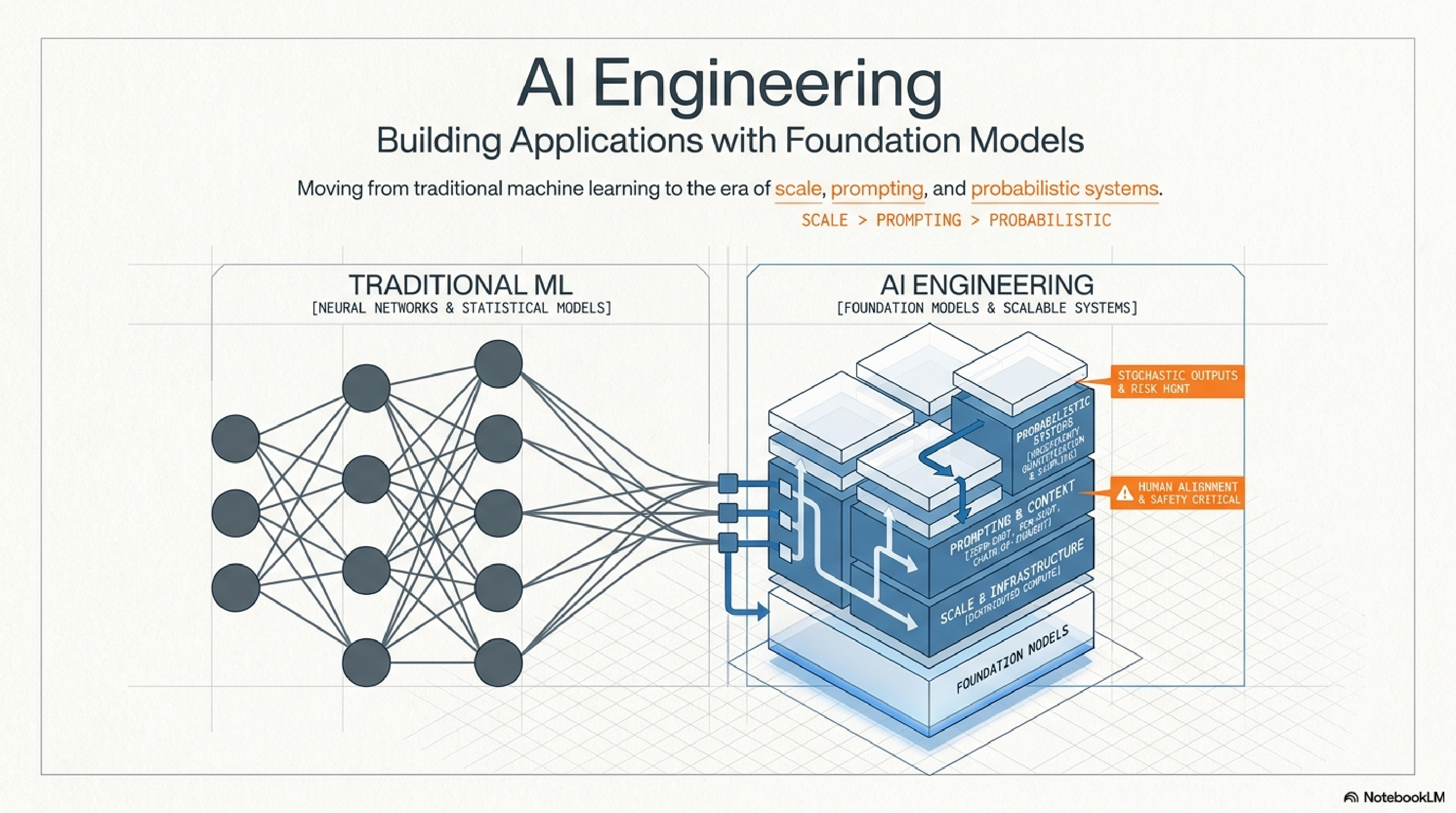
Most people in 2026 still think AI work means writing better prompts. That is the smallest, least interesting layer of the entire stack. The real job, the one nobody at the dinner party can describe, is engineering a probabilistic system to behave deterministically enough to ship to a paying customer.
This letter walks through the fifteen frames I use to think about that job. They cover the whole map: scaling laws, transformer mechanics, post-training, sampling, structured output, hallucinations, and the evaluation crisis that quietly eats most AI startups alive. If you read every section and look at every diagram, you will understand AI engineering at the level of someone shipping it for a living. That is the promise.
1. The paradigm shift.
Traditional ML was a craft of training small bespoke models from scratch on tabular data. AI engineering is the opposite shape. You start with a foundation model that already cost someone else nine figures to train, and your entire job is adapting, constraining, and evaluating it inside a real product.
The discipline pivots on three new axes. Scale: you are renting compute, not buying it. Prompting: the instruction is now a first-class artifact. Probabilistic: the same input produces different outputs, and your system has to survive that. If your team still talks about "training the model" before talking about evals, they are solving last decade's problem.
2. The core delta.
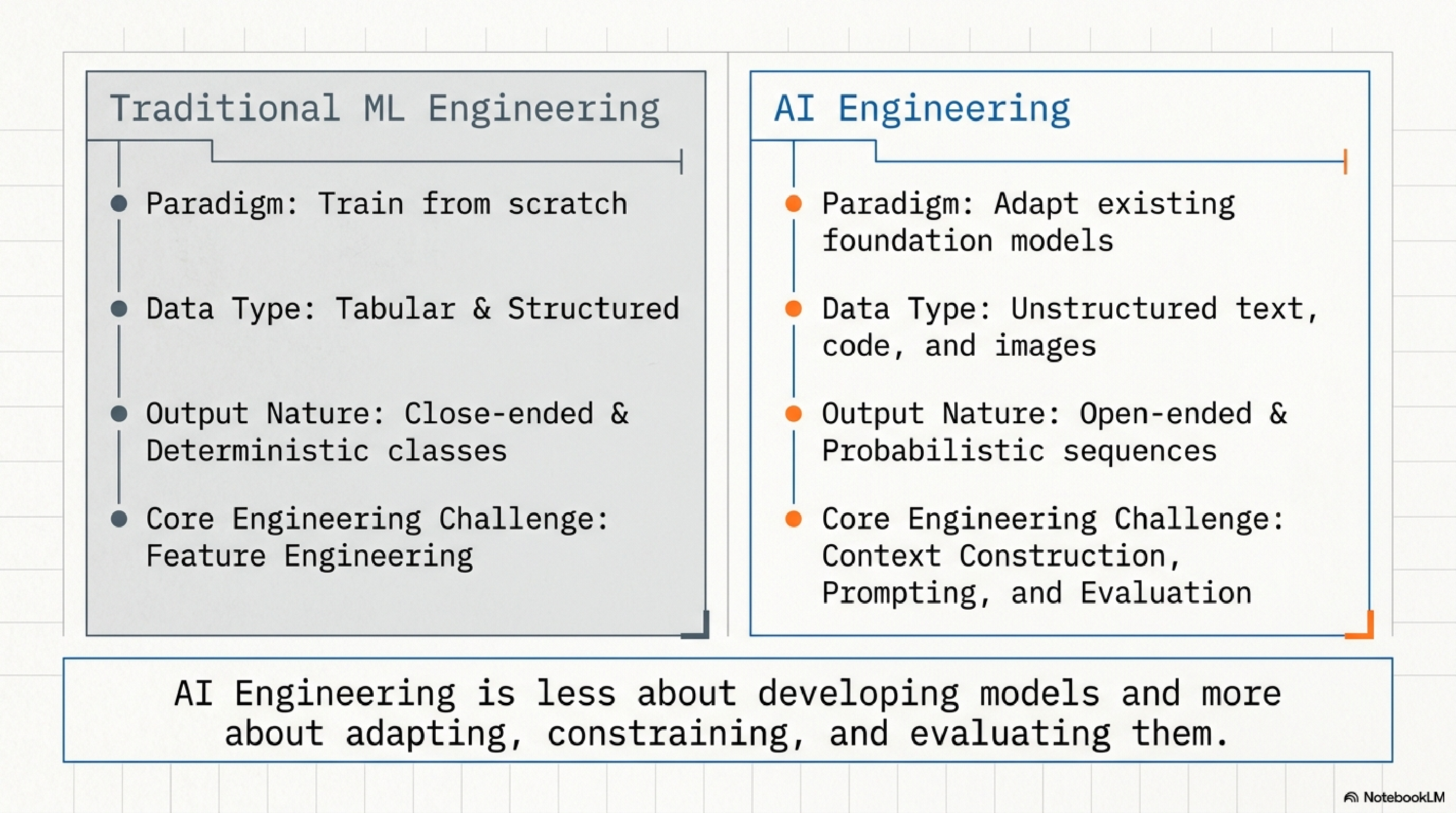
Read this one twice. The phrase "AI Engineering is less about developing models and more about adapting, constraining, and evaluating them" is the entire job description. If you can internalize that one sentence, you will stop hiring the wrong people and stop building the wrong tools.
Feature engineering used to be where the value was created. Today the value lives in context construction, prompting, and evaluation. Those three are the new feature engineering, and most teams are catastrophically underinvested in all three.
3. The stack.
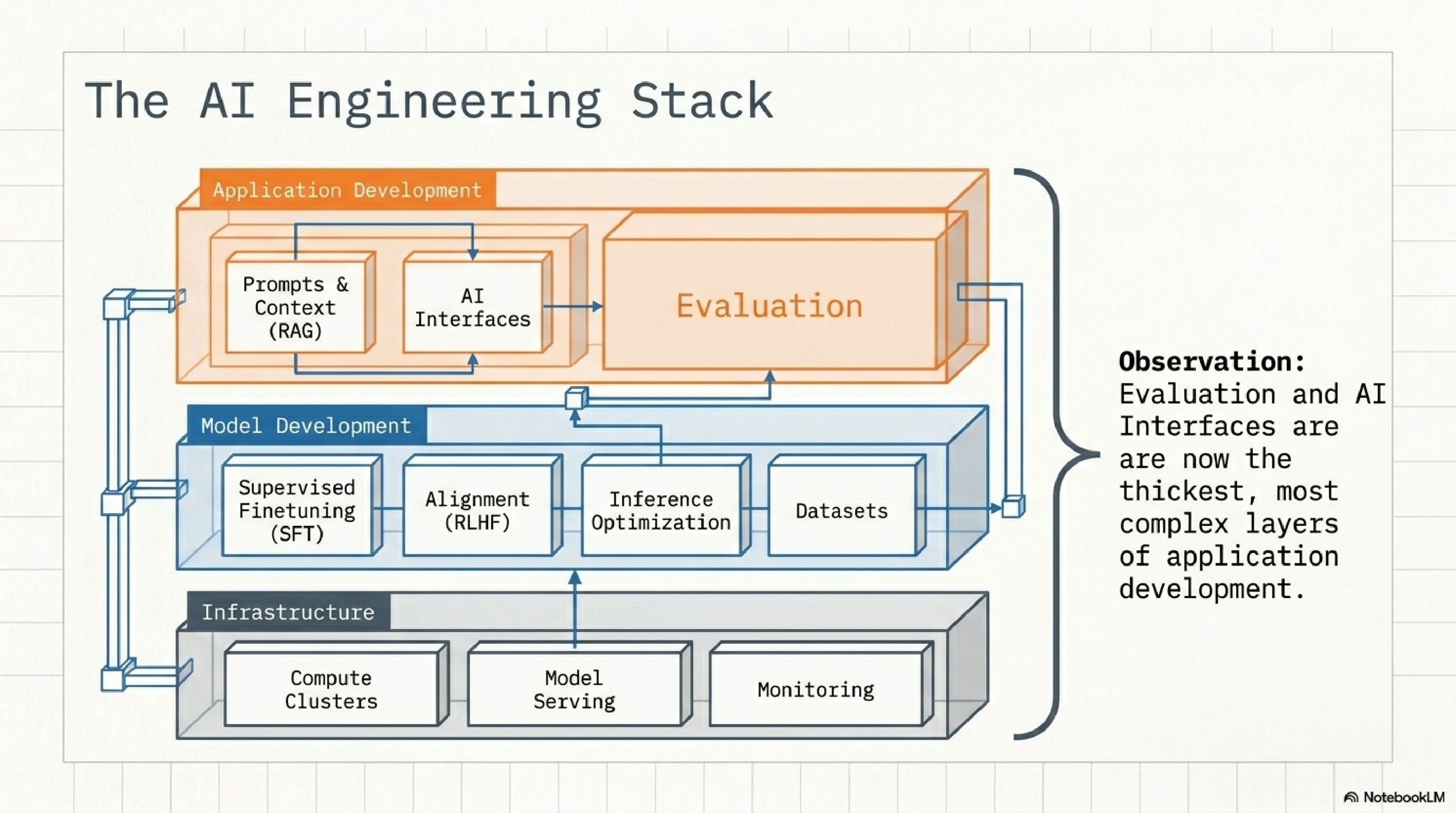
Three layers. Infrastructure at the bottom: compute, serving, monitoring. Model development in the middle: SFT, alignment, inference optimization, datasets. Application development on top: prompts and context (RAG), AI interfaces, and evaluation.
Notice which boxes the diagram draws thickest at the top. Evaluation and AI Interfaces. That is not a stylistic choice. That is the observation that for a startup building on top of foundation models, almost all the leverage is in those two boxes. If you are spending most of your time below the application layer, you are doing somebody else's job.
4. The physics of AI.
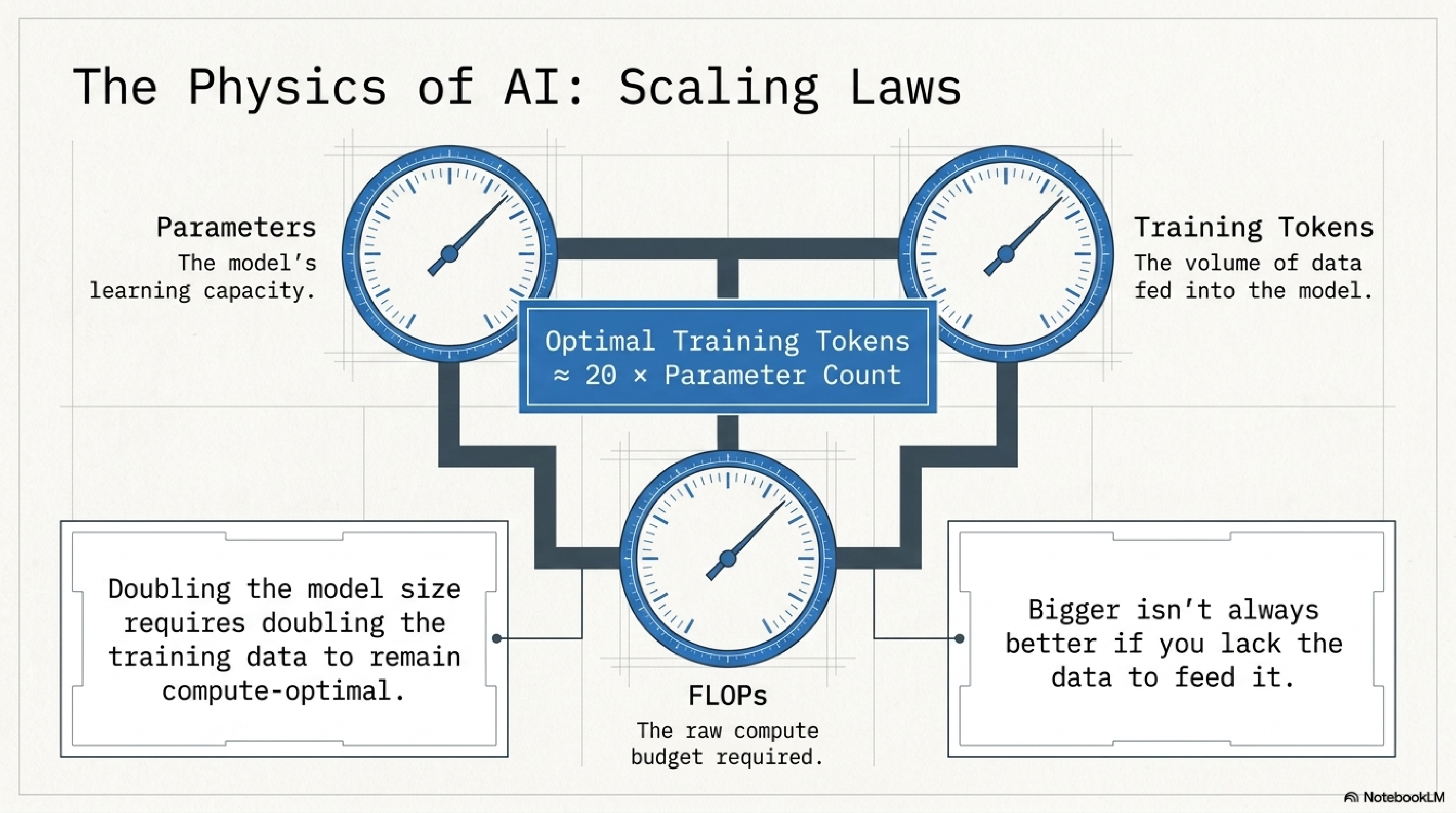
The single most important number in modern AI: roughly 20 tokens of data per parameter for a compute-optimal training run. This is the Chinchilla finding restated, and it is why the "just make the model bigger" era ended around 2023.
The practical takeaway for an operator: bigger models without bigger and cleaner data are a waste of compute. When you read about a frontier model release, look at tokens trained, not parameter count. The lab that 5x'd the data on the same parameters will eat the lab that 5x'd the parameters on the same data.
5. The representation gap.

If your product serves a non-English market, this slide is your unit economics. English gets 2 tokens for "Hello World." Burmese gets 20. The same user query costs you 10x more in API fees and runs 10x slower, before you have written a single line of code.
I see Western founders ignore this constantly. Then they expand to Indonesia or Vietnam and their margins quietly evaporate. The fix is not "switch model." The fix is to budget for the tokenization tax up front and design caching, summarization, and language-specific prompts to neutralize it.
6. The engine.
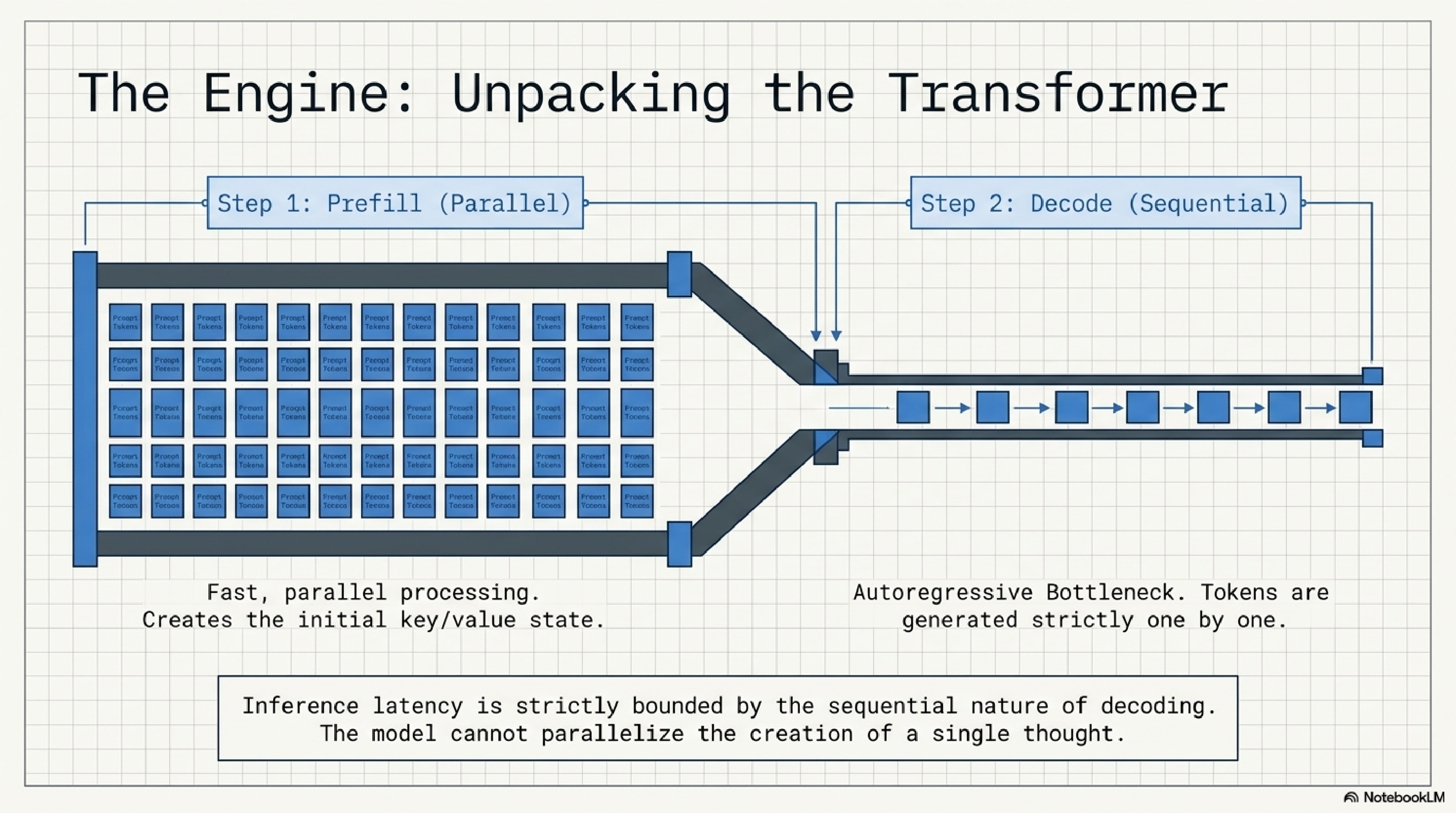
Two phases inside every transformer call: prefill (parallel, fast, eats your input) and decode (sequential, slow, generates one token at a time). The decode step is autoregressive by definition. The model cannot parallelize the creation of a single thought.
This is why streaming feels fast even when total latency is high. It is also why short outputs are dramatically cheaper than long ones, and why "generate a 5,000 token plan" is a bad pattern for any latency-sensitive product. Architect around the decode bottleneck or get punished by it.
7. The post-training pipeline.
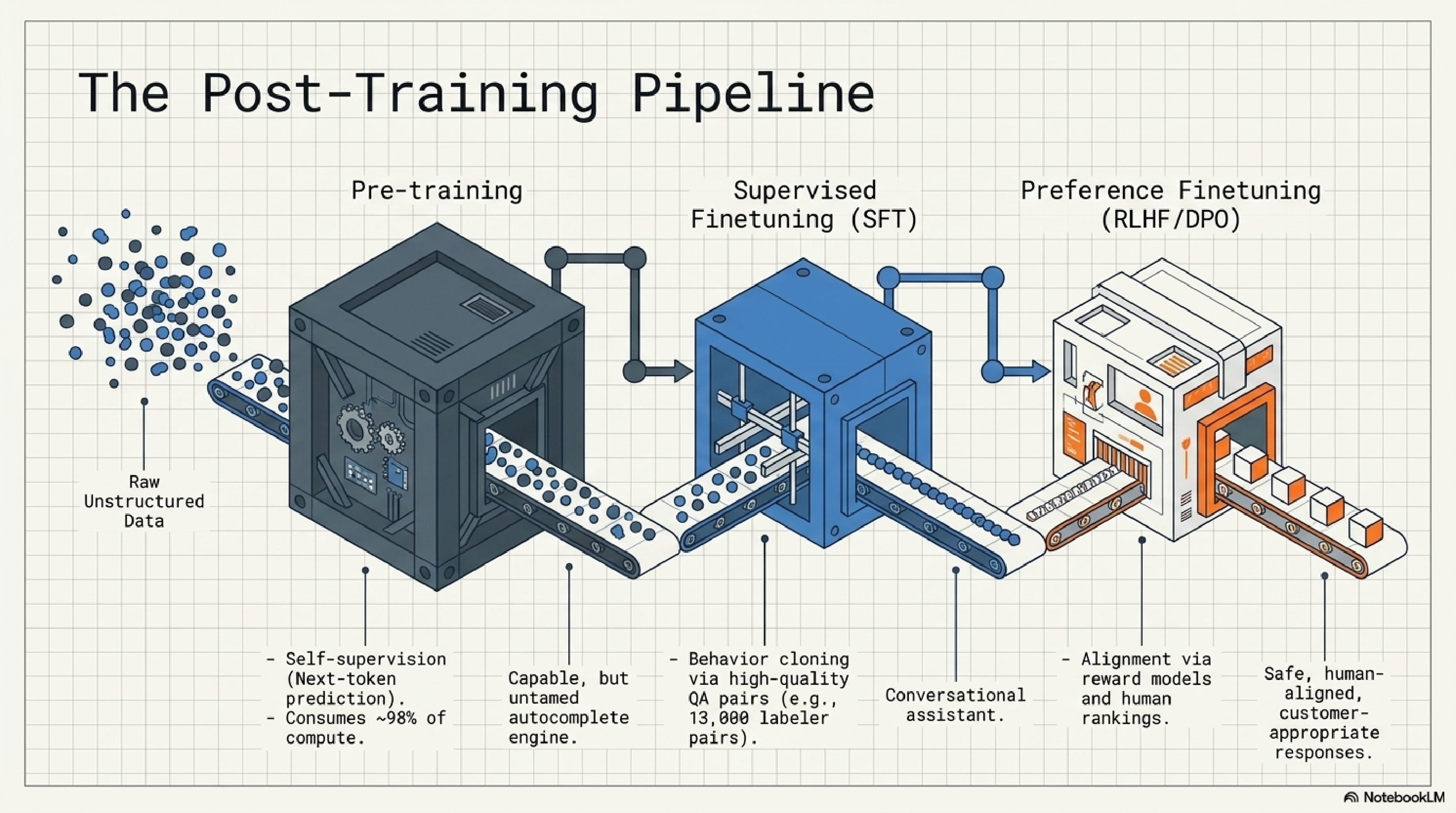
The model that costs $100M to train is the autocomplete engine. The model you actually use as a chat assistant is that engine plus two relatively cheap layers on top: supervised finetuning on roughly 13,000 high-quality QA pairs, then preference finetuning via human rankings (RLHF or DPO).
This matters because almost all the personality, safety, and helpfulness of a model lives in those last two stages. Open-weight bases are usable but feral. The "magic" of GPT, Claude, and Gemini is mostly the alignment pass. When you finetune, you are doing a smaller version of the same trick.
8. The mechanics of generation.
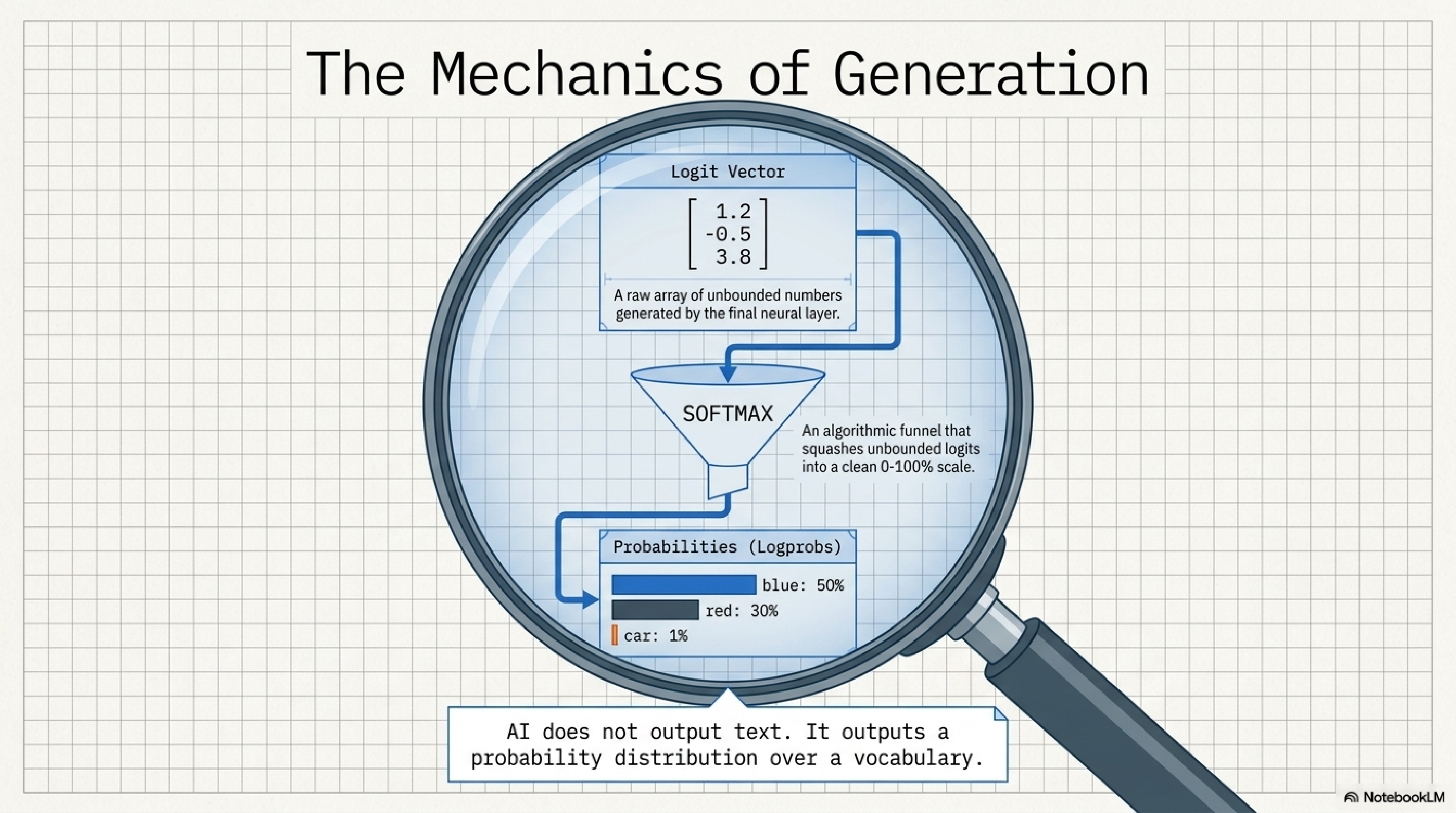
The most important mental model to internalize. The LLM does not output words. It outputs a probability distribution over its vocabulary. A vector of raw logits goes through a softmax and you get back a list of every possible next token with a percentage attached.
Once you see this clearly, every other piece of the puzzle clicks. Sampling, hallucination, structured output, evaluation, all of them are downstream consequences of one fact: the model is a probability machine, and we are constantly wrapping it in heuristics to make it look like a writer.
9. Sampling strategies.
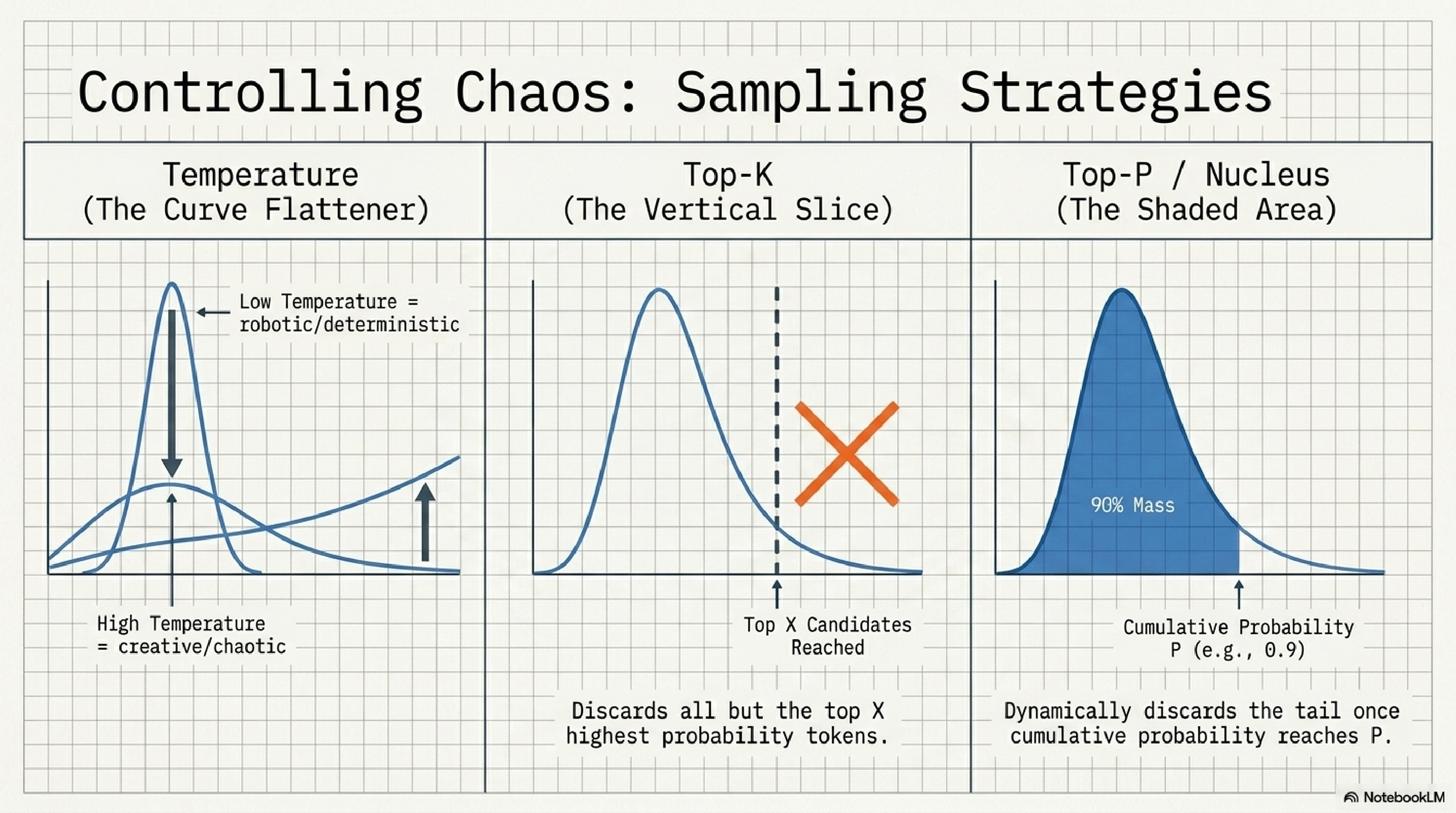
Three knobs that decide how the model picks from that probability distribution. Temperature reshapes the curve: low is sharp and deterministic, high is flat and creative. Top-K draws a hard line at the K most likely tokens. Top-P draws a soft line at whatever tokens cover the top P% of probability mass.
Practical settings: temp 0 for extraction and classification, temp 0.3 to 0.7 for assistant-style writing, top-p 0.9 with temp 0.7 for generative content. Temp 1.5 for brainstorming when you need surprise. Anyone who tells you "lower temperature equals more accurate" without context is bluffing.
10. Test-time compute.
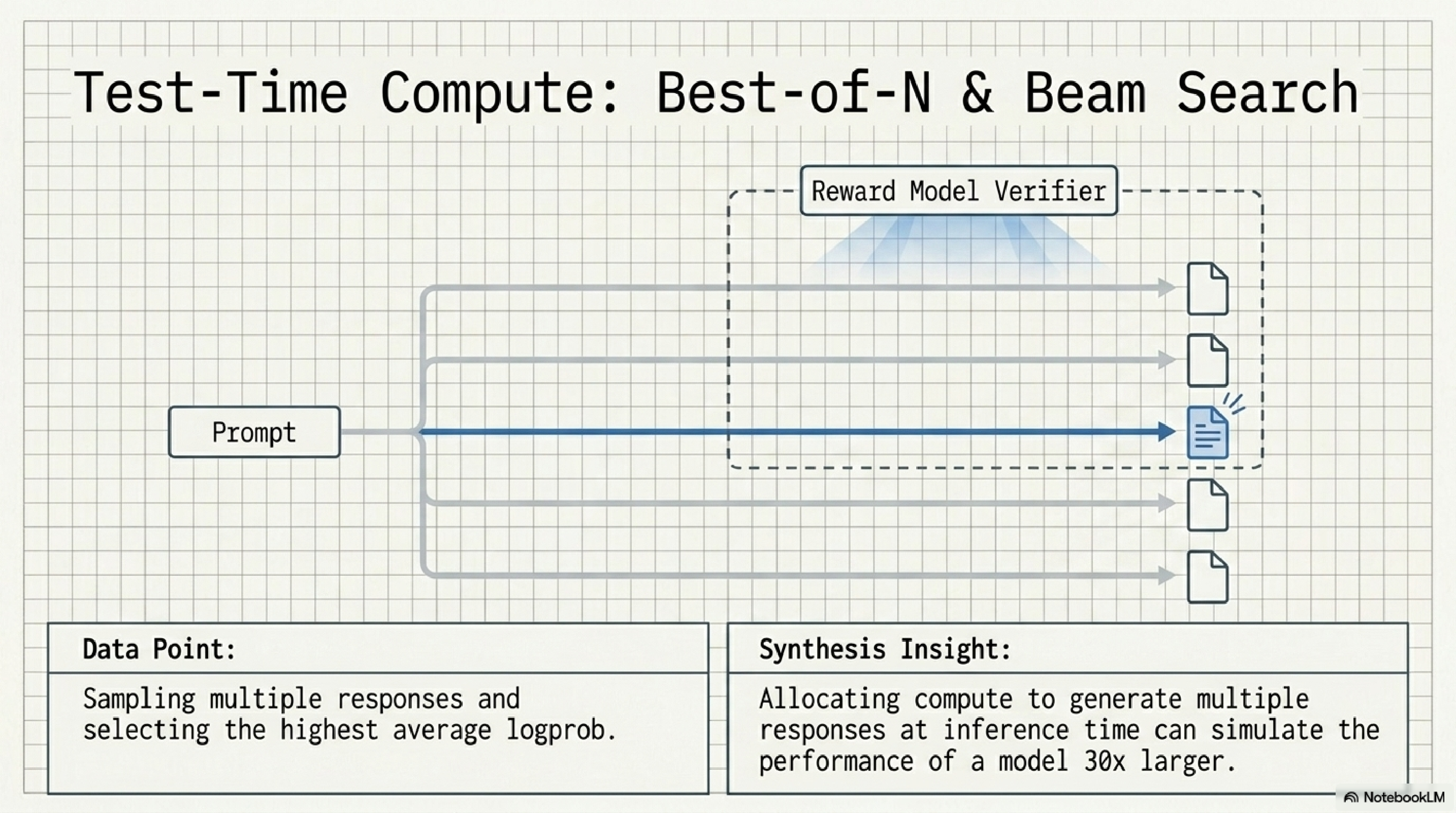
This is the trick behind most of the 2024-2026 reasoning model jump. Instead of relying on the model to nail the answer in one pass, you generate N answers, score them with a verifier, and ship the best one. It is shockingly effective.
The headline number: a Best-of-N or beam search loop at inference time can simulate the performance of a model 30x larger. For a startup, this is enormous leverage. You do not need a frontier model for hard reasoning if you are willing to spend the inference budget. Most teams have not even started thinking this way.
11. The structuring problem.
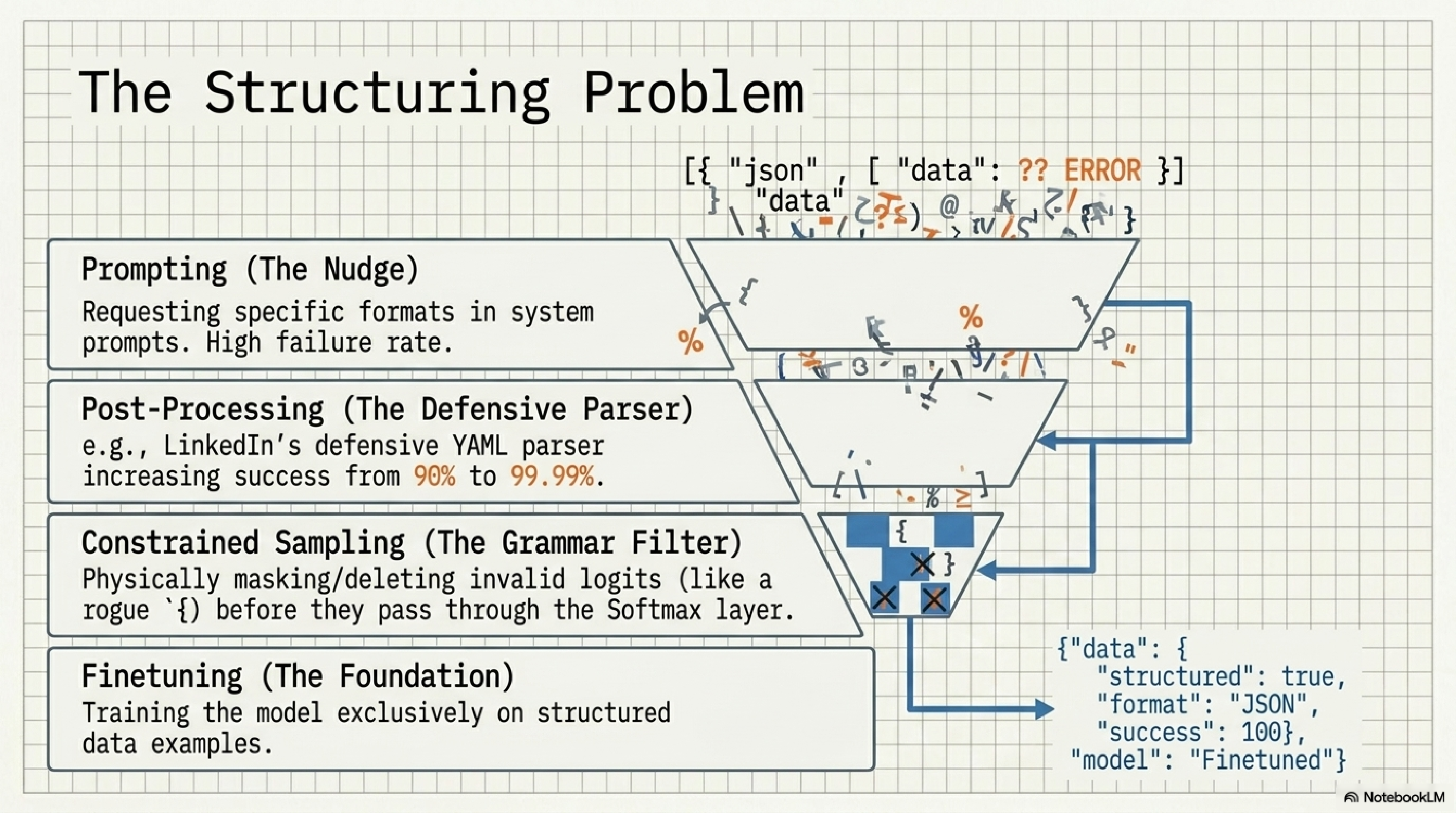
Every team that ships an AI product hits this wall: the model gives you slightly broken JSON 1-5% of the time, and your pipeline collapses on that 1-5%. There is a clean ladder of fixes, and you climb it in this order: prompting, defensive parsing, constrained sampling, finetuning.
Constrained sampling is the underrated weapon. You physically mask invalid tokens at the logit layer so the model literally cannot produce a malformed brace. LinkedIn famously took success from 90% to 99.99% with a defensive YAML parser alone. If your product depends on structured output, you should know the entire ladder cold.
12. The probabilistic tax.
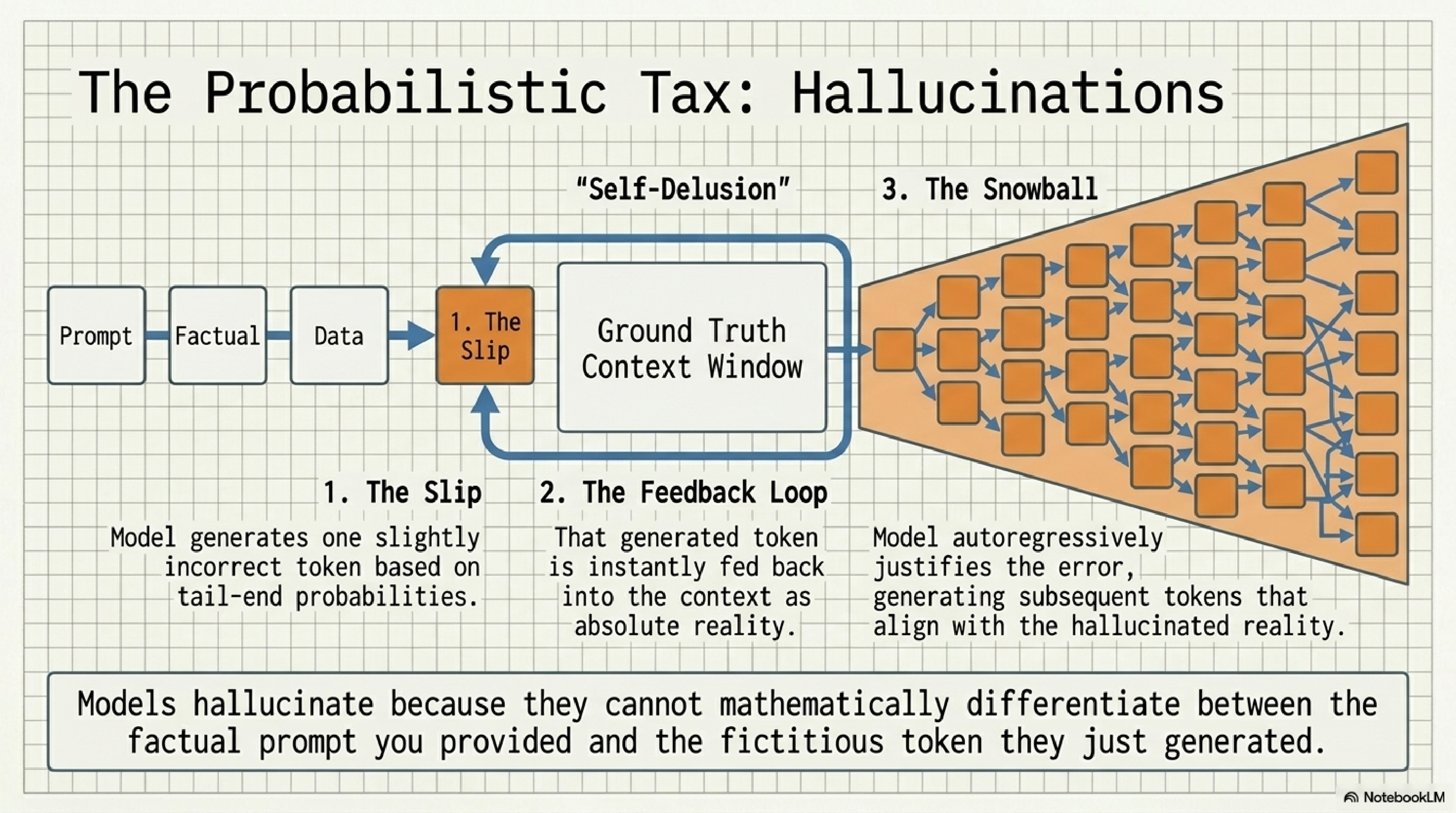
Hallucination is not a bug, it is a structural property of autoregressive generation. The model picks a slightly wrong token from the tail of the distribution. That token is instantly fed back into the context as if it were ground truth. Every subsequent token is now conditioned on a fact the model invented one step ago. Error compounds.
This is why short, well-grounded prompts hallucinate less than long open-ended ones, and why retrieval augmentation works. You are not curing hallucination, you are starving it. The defensive moves are: shorter generations, citations forced into context, verifier passes on output, and refusing to ask the model open-ended factual questions in the first place.
13. The evaluation crisis.
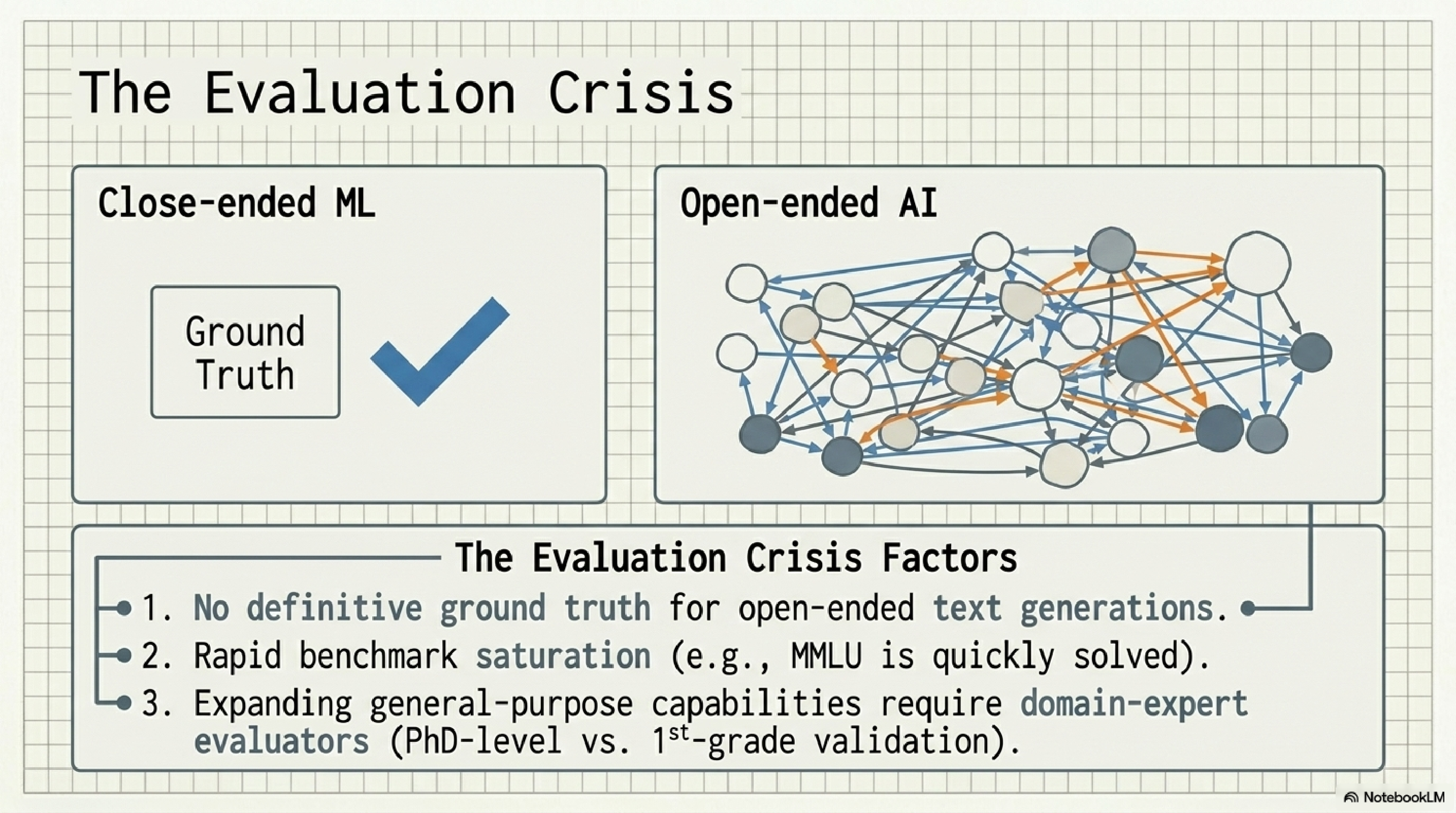
This is the one that quietly kills startups. With open-ended generation there is no single right answer. Benchmarks saturate within a year. And as models get smarter, evaluating their output requires people smarter than the median user, sometimes PhDs.
The implication for builders is uncomfortable: your eval system is probably your most underbuilt asset. If you are not running a regression suite of golden examples on every prompt change, you are flying blind. The teams that will dominate the next two years are not the ones with the best prompt. They are the ones with the best evals.
14. Entropy and perplexity.

Entropy measures the surprise carried by a single token. Perplexity measures the model's average uncertainty when predicting the next one. They are two views of the same underlying number.
The reason this matters in 2026: perplexity is the ultimate lie detector for benchmark contamination. If a model has suspiciously low perplexity on a public benchmark, it almost certainly saw that benchmark during training. Half the model rankings on Twitter are noise produced by leaderboards measuring memorization. Once you know to look for it, you cannot unsee it.
15. Exact vs. similarity evaluation.
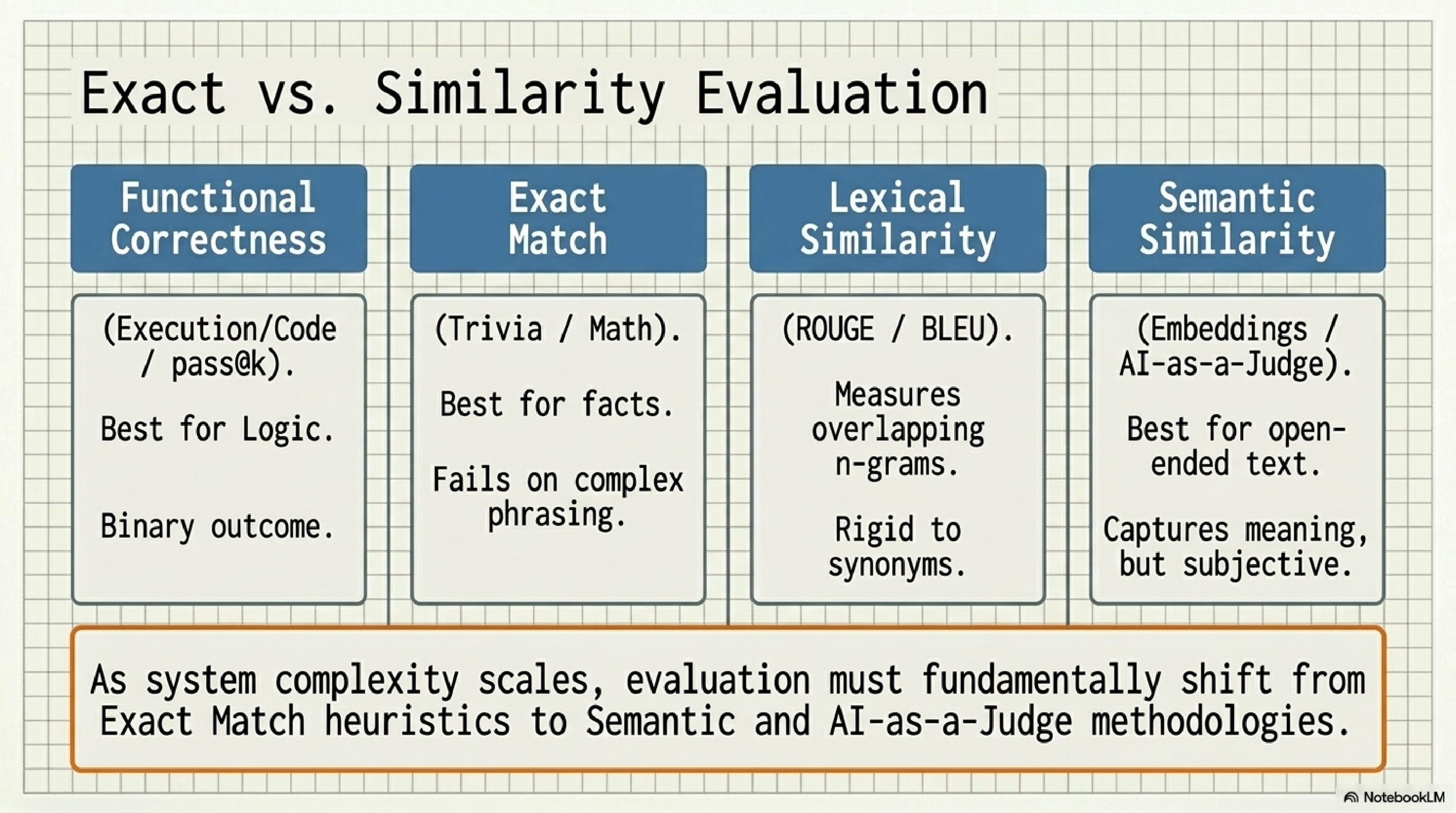
Four rulers, four jobs. Functional correctness for code and logic: did the test pass. Exact match for facts and math: is the string identical. Lexical similarity (ROUGE, BLEU) for translation-style tasks: how much n-gram overlap. Semantic similarity for open-ended generation: does the meaning match.
The trap is that exact-match evals are easy to build, so most teams stop there. As your system gets more open-ended, exact-match becomes a worse and worse proxy for what users care about. You have to graduate to semantic similarity and AI-as-a-judge, and you have to do it before your eval scores start lying to you.
What this actually means for builders.
If you scrolled this far, here is the compression of the entire field into five non-negotiable beliefs.
- The model is a probability machine. Every other concept (sampling, hallucination, structured output) is a wrapper around that one fact.
- The leverage is in the application layer. Context, prompts, and evals do more for your product than swapping model providers.
- Decode is the bottleneck, tokens are the tax. Architect for short outputs and budget for non-English token bloat from day one.
- Test-time compute is the cheat code. Best-of-N and verifier loops simulate a model 30x larger for the cost of a few extra calls.
- Your evals are your moat. Whoever has the best regression suite of golden examples wins the next two years.
I am building three products on top of this stack right now (Replaceability Index, an internal sales agent, and a fitness coach). Every section above is something I learned the expensive way. The frames are free. The reps are not.
If this letter was useful, the next ones will be too. They go out twice a week and cost you nothing.
Shoh.